ICLR 2019热议论文Top 5:BigGAN、斗地主深度学习算法等
2018-10-01 17:49 来源:新智元 分数 /化学 /爱奇艺
原标题:ICLR 2019热议论文Top 5:BigGAN、斗地主深度学习算法等

爱奇艺
新智元推荐
来源:专知(ID: Quan_Zhuanzhi)
【新智元导读】国庆佳节第一天,举国同庆!出门旅游想必到处都是人山人海,不如在家里看看论文也是极好的!近日,机器学习顶会之一的ICLR2019投稿刚刚截止,本次大会投稿论文采用匿名公开的方式。本文整理了目前在国外社交网络和知乎上讨论热烈的一些论文,一起来看看!
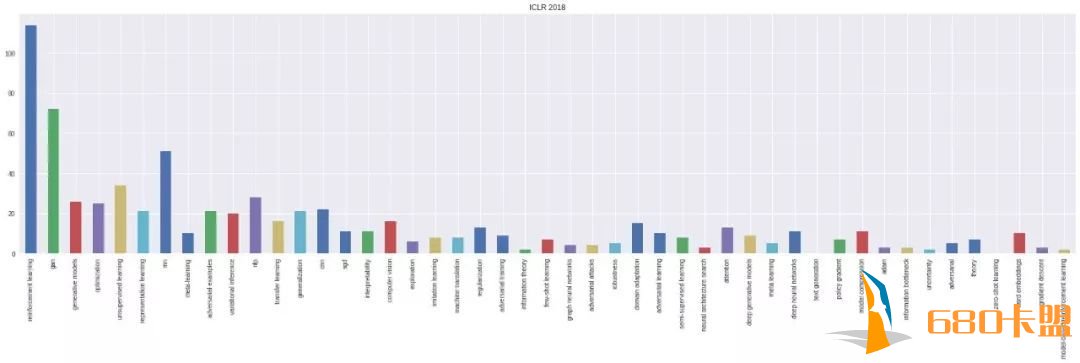
首先我们来看看ICLR 2018,也就是去年的提交论文题目分布情况。如下图所示。热门关键词:强化学习、GAN、RIP等。
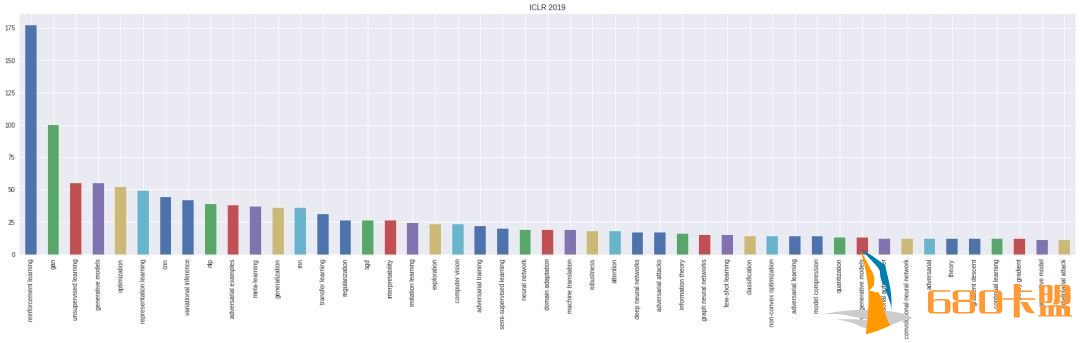
上图为ICLR 2019提交论文的分布情况,热门关键词:强化学习、GAN、元学习等等。可以看出比去年还是有些变化的。
投稿论文地址:
https://openreview.net/group?id=ICLR.cc/2019/Conference
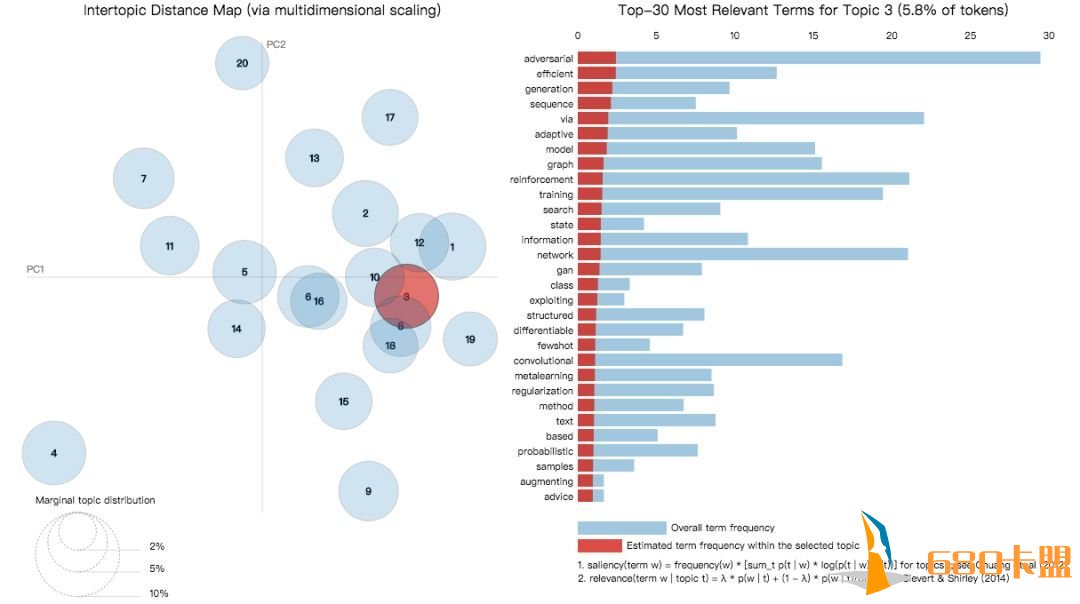
在Google Colaboratory上可以找到关于ICLR 2019提交论文话题之间更加直观的可视化图。我们选择了上图中排名第三的话题“GAN”,图中由红色表示。可以看出,排名第三的GAN与表中多个话题有交集,如training、state、graph等。
讨论热度最高的论文TOP 5
1. LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS
最强GAN图像生成器,真假难辨

论文地址:
https://openreview.net/pdf?id=B1xsqj09Fm
更多样本地址:
https://drive.google.com/drive/folders/1lWC6XEPD0LT5KUnPXeve_kWeY-FxH002
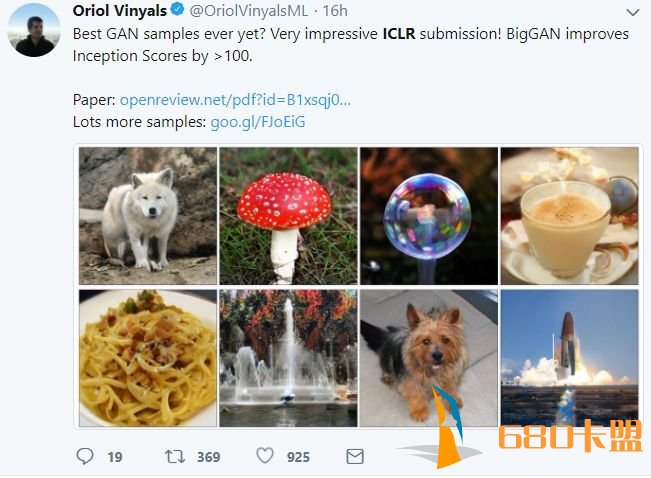
第一篇就是这篇最佳BigGAN,DeepMind负责星际项目的Oriol Vinyals,说这篇论文带来了史上最佳的GAN生成图片,提升Inception Score 100分以上。
论文摘要:
尽管近期由于生成图像建模的研究进展,从复杂数据集例如 ImageNet 中生成高分辨率、多样性的样本仍然是很大的挑战。为此,研究者尝试在最大规模的数据集中训练生成对抗网络,并研究在这种规模的训练下的不稳定性。研究者发现应用垂直正则化(orthogonal regularization)到生成器可以使其服从简单的「截断技巧」(truncation trick),从而允许通过截断隐空间来精调样本保真度和多样性的权衡。这种修改方法可以让模型在类条件的图像合成中达到当前最佳性能。当在 128x128 分辨率的 ImageNet 上训练时,本文提出的模型—BigGAN—可以达到 166.3 的 Inception 分数(IS),以及 9.6 的 Frechet Inception 距离(FID),而之前的最佳 IS 和 FID 仅为 52.52 和 18.65。
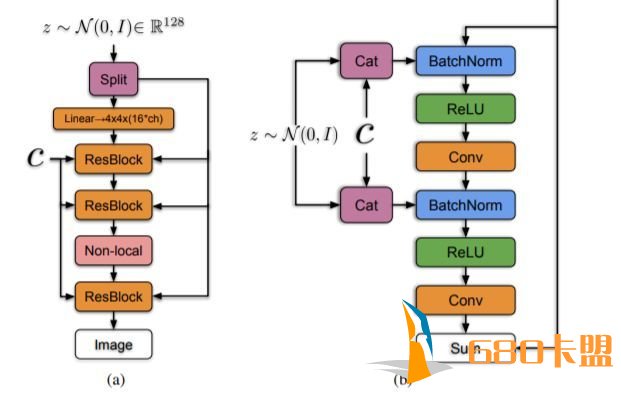
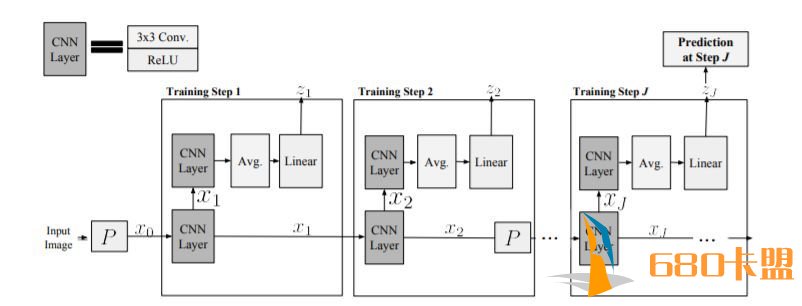
BigGAN的生成器架构

生成样例,真是惟妙惟肖
2. Recurrent Experience Replay in Distributed Reinforcement Learning
分布式强化学习中的循环经验池

论文地址:
https://openreview.net/pdf?id=r1lyTjAqYX
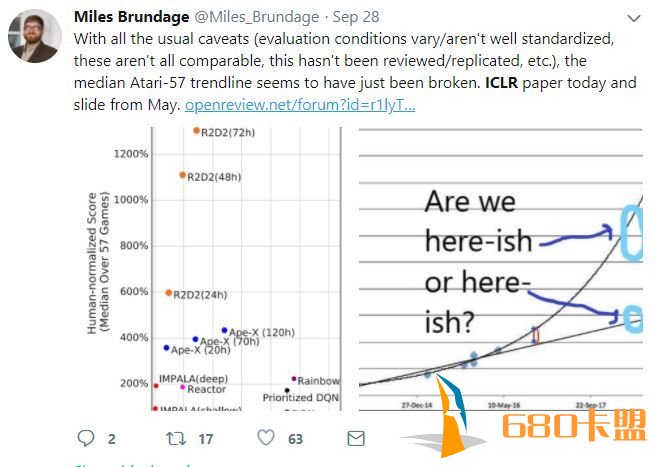
Building on the recent successes of distributed training of RL agents, in this paper we investigate the training of RNN-based RL agents from experience replay. We investigate the effects of parameter lag resulting in representational drift and recurrent state staleness and empirically derive an improved training strategy. Using a single network architecture and fixed set of hyper-parameters, the resulting agent, Recurrent Replay Distributed DQN, triples the previous state of the art on Atari-57, and surpasses the state of the art on DMLab-30. R2D2 is the first agent to exceed human-level performance in 52 of the 57 Atari games.
3. Shallow Learning For Deep Networks
深度神经网络的浅层学习

论文地址:
https://openreview.net/forum?id=r1Gsk3R9Fm